

Autoencoder
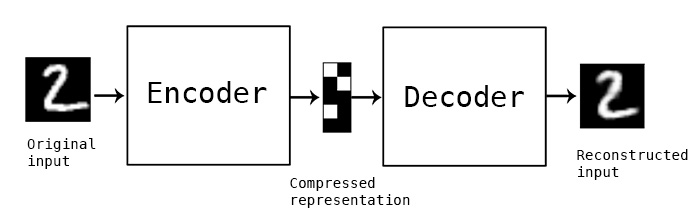
在一個標準的 autoencoder 裡,有兩個部份: Encoder(編碼器) 和 Decoder(解碼器),Encoder 將 input (這篇文章將以手寫辨識圖片作為例子),映射成 latent representation (可以想成一個向量),而 Decoder 的目的是再將這個向量重新還原成原始的圖片。
因此 Autoencoder 可以做到將一張圖片壓縮成一個較低維度的 latent representation。就像我們的人腦一樣,看到一張圖片,我們只需要記住一些”特徵”、”概念”,而不需要把每一個細節、像素都記下來,下次再看到同一張圖片仍能認得出來。
但是一個標準的 Autoencoder 會有一個問題 : 中間的 latent representation 能夠 “有效的” 代表那張圖片嗎?Autoencoder可能只是死記硬背下這個 latent representation,當這個 latent representation 因為雜訊而有微小的更動,那麼 Decoder 很有可能將完全認不得,因而造成 output 出來的結果是爛的。
因此我們有了 Variational Autoencoder (VAE)
Variational Autoencoder (VAE)
- 一般的 Autoencoder 將 input data 映射成 latent representation
- Varational Autoencoder 將 input data 映射到 distribution 的參數,像是高斯分佈的 mean 和 variance。

VAE 將不再只是產生一個無聊的、單一的向量來代表原來的圖片,而是產生一個 Gaussain Distribution,並且用他的平均值 (?) 及標準差 (?) 來代表。
以下是 Variational Autoencoder 的工作流程:
- 一張圖片會被 VAE 的 Encoder 映射到 Gaussian Distribution 的 ? 和 ?
- 從以 ? 和 ? 代表的 Gaussian Distribution中抽取一個數值代表 latent variable
- VAE 的 Decoder 再透過這個 latent variable 建構出原來的圖片
這讓 VAE 學到一個更平滑的 latent representation,因此如果今天稍微更動了中間的 latent representation,我們不會得到一張爛掉的圖片,而是一個稍微不一樣的圖片(可能有顏色變化、角度變化等等)。這就是 VAE 強大的地方。
Tensorflow2 實做 VAE
先 import 我們需要的套件
import tensorflow as tf
import numpy as np手寫數字辨識 MNIST 資料集
讀取手寫數字辨識資料集MNIST
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# x_train.shape : (60000, 28, 28)
# x_test.shape : (10000, 28, 28)將手寫數字圖片做前處理(preprocessing)
def preprocess_images(images):
images = images.reshape((images.shape[0], 28, 28, 1)) / 255.
images = np.where(images > .5, 1.0, 0.0).astype('float32')
return images
train_images = preprocess_images(x_train)
test_images = preprocess_images(x_test)
# train_images.shape : (60000, 28, 28, 1)
# test_images.shape : (10000, 28, 28, 1)tf.data.Dataset
使用 tf.data.Dataset 定義資料集,包含定義 batch size 和 shuffle 資料
train_size = train_images.shape[0] # 60000
test_size = test_images.shape[0] #10000
batch_size = 32
train_dataset = (tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(train_size).batch(batch_size))
test_dataset = (tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(test_size).batch(batch_size))定義 Variational Autoencoder
tf.keras.Sequential
VAE 架構:
- Encoder : 將 input 圖片映射成 latent representation z
- input : x (圖片)
- output: Gaussian Distribution 的 ? 和 ? 。
- Decoder : 將 latent representation z 作為 input,output 出 image
- input : z (從 Gaussian Distribution 中 sample 值出來)
- output : x (圖片)
很明顯可以看到 Encoder 和 Decoder,input 和 output 的東西剛好反過來,以整體 Autoencoder來說,是將一張圖片同時作為 input 和 output,這就是為什麼 Autoencoder 可以做到 Unsupervised Learning 非監督式學習的原因。在這個例子中,我們將使用Convolution Neural Network 來搭建 Encoder 和 Decoder。
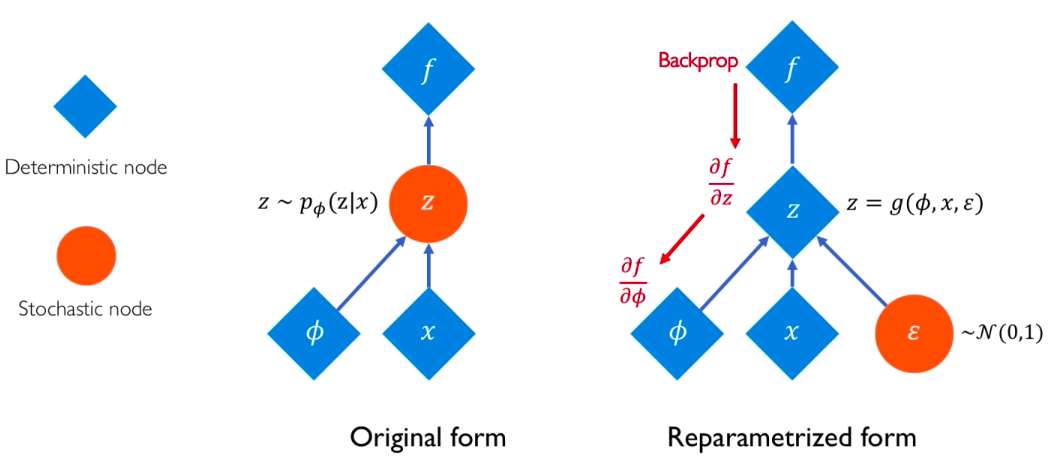
Reparameterization trick:
在訓練時,為了讓 Decoder 吃 latent representation z,我們可以從Encoder output 出來的 Distribution 參數來 sample,但是會有一個問題 : 在做 backpropagation 時,沒辦法讓gradient(梯度) 流過這個不能微分的地方。因此需要引入一個 reparameterization 的技巧。
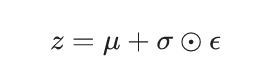
使用 Encoder output的 ? 和 ? 以及一個額外引入的隨機 ε (也是從 Gaussain中抽出),來代表這個 latent representation z。
class VAE(tf.keras.Model):
# Variational Autoencdoer
# Encoder : 兩層 Convolutional layers
# Decoder : 三層 Convolutional layers
def __init__(self, latent_dim):
super(VAE, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# No activation
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
self.decoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filters=64, kernel_size=3, strides=2, padding='same',
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filters=32, kernel_size=3, strides=2, padding='same',
activation='relu'),
# No activation
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=1, padding='same'),
]
)
@tf.function
def sample(self, eps=None):
if eps is None:
eps = tf.random.normal(shape=(100, self.latent_dim))
return self.decode(eps, apply_sigmoid=True)
def encode(self, x):
mean, logvar = tf.split(self.encoder(x), num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z, apply_sigmoid=False):
logits = self.decoder(z)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
return logits定義 Loss Function
VAE 想做到的是最大化 ELBO(evidence lower bound)
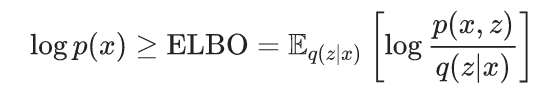
實作上,會去 Optimize
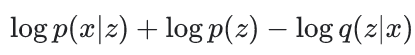
關於ELBO,這是一門大學問,背後有很多的理論背景支持。我們日後將寫一篇文章專門介紹。關於VAE的架構、訓練流程及其精神我們介紹到這邊,詳細的程式碼請見 Tensorflow 官方教學:
參考資料
- Tensorflow 官方教學文章
- MIT 線上課程 : Deep Generative Modeling | MIT 6.S191
- “Reparameterization” trick in Variational Autoencoders