
原始論文連結
WaveNet: A Generative Model for Raw Audio

WaveNet 介紹
WaveNet 在 2016 年由 Google 的 DeepMind 提出,是一個直接生成 raw audio 的深度學習模型。 Google 也有提供語音合成 API 讓你可以輸入文字產生自然的人類語音。有趣的是,使用WaveNet 的 API 是比較貴的,因此可以看出 Google 開發出 WaveNet 不僅推進了語音合成的進展,也為Google 帶來商業利益。( 筆者在寫這篇文章時,WaveNet 仍然是State of the art,多數的語音合成模型仍是 based on WaveNet)

WaveNet 架構

受到 PixelRNN 在影像應用上生成 pixels 的啟發,WaveNet 將相似的概念應用於語音生成上,並且可以處理 resolution 至少為每秒 16,000 個 sample 的訊號。WaveNet 的架構是 autoregressive 的,亦即每個時間點的訊號都是根據過去的訊號所產生, waveform x = {x1,…,xT} :
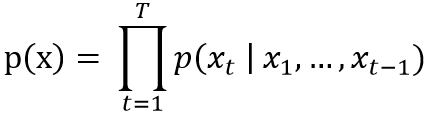
Dilated Causal Convolution (擴展因果卷積)
WaveNet 架構的核心是 dilated causal convolution:
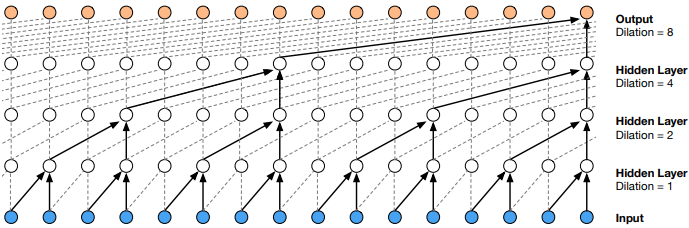
Dilated causal convolution有以下幾個特點:
- Causality 因果性 : 每個在 timestep t 的訊號都是根據過去的 input 所產生,不會看到未來的 data。也就是說,$latex p(x_{t+1} | x_{1}, … , x_{t})$ 不會看到 $latex x_{t+1}, x_{t+2}, … , x_{T}$
- Dilated convolution 擴展卷積: 相較於一般的convolution,dilated convolution 在做convolution 時會忽略特定 step 的 input,雖然這樣會讓看到的 input 比較稀疏,但是同樣的運算時間可以看到時間尺度上更廣的 data,增加 receptive field。
- Fast Training: 因為 WaveNet 的模型架構不是 recurrent (遞歸)的,所以訓練時較RNN快。Inference 時,因為 autoregressive 的性質,每個預測出來的 output 都會當作 input 再送回模型裡,速度會較慢。有一些方法在後來提出來解決速度預測速度慢的問題,例如 Fast WaveNet、Parallel WaveNet 等等。
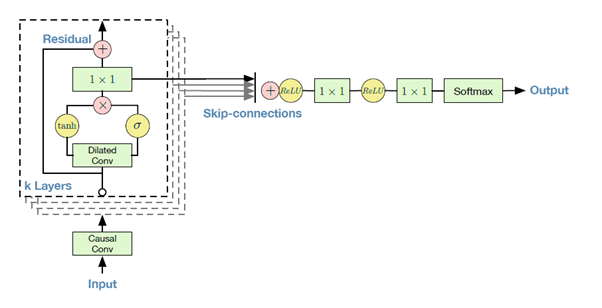
Residual and skip-connections
為了讓 WaveNet 可以使用更多層的架構 (更深),以及收斂速度更快。WaveNet 使用Residual 的架構以及 Skip-connections。如下圖:
Text-to-speech
若要讓 WaveNet 做 Text-to-speech,則需要給定文字的information h 來產生 raw audio。
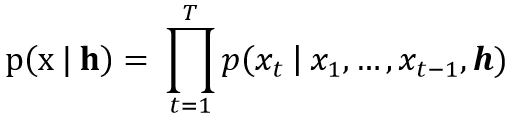
WaveNet 實驗結果
原始論文中,使用 Google 的 North American English Dataset 和 Mandarin Chinese Dataset。 North American English Dataset 包含 24.6 小時的 speech data;Mandarin Chinese Dataset 包含 34.8 小時的 speech data。 並且使用 Mean Opinion Scores (MOS) 衡量成效。 在 MOS tests 裡,受測者在聽完語音後可以他打 1 ~ 5 分,越高分代表品質越好(1: Bad, 2: Poor, 3: Fair, 4: Good, 5: Excellent)。 相較於 concatenative 和 parametric的方法有非常大的進步 (請參考語音合成 Part1 – Text-to-speech介紹)。

Reference
- Oord, Aaron van den, et al. “Wavenet: A generative model for raw audio.” arXiv preprint arXiv:1609.03499 (2016).
- Oord, Aaron van den, Nal Kalchbrenner, and Koray Kavukcuoglu. “Pixel recurrent neural networks.” arXiv preprint arXiv:1601.06759 (2016).
- Paine, Tom Le, et al. “Fast wavenet generation algorithm.” arXiv preprint arXiv:1611.09482 (2016).
- Oord, Aaron van den, et al. “Parallel wavenet: Fast high-fidelity speech synthesis.” arXiv preprint arXiv:1711.10433 (2017).
- He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.