

Text-to-speech (TTS) 簡介
你是不是也有在使用 Google 翻譯的時候,讓 Google 小姐把你打的文字念出來? 這種文字轉換成語音的技術稱為文字轉語音 Text To Speech,簡稱 TTS。Text-to-speech (TTS) 的目標是將給定的文字 (text) 合成出對人類來說自然的語音 (speech)。
傳統上有兩種方法來實現 TTS,分別是拼接式合成 (concatenative speech synthesis) 和參數式合成 ( parametric speech synthesis )。隨著人工智慧、深度學習的發展,Google DeepMind 於 2016 年提出 WaveNet,讓合成出來的語音更自然、更像人聲,讓 Google 小姐的聲音有了全面性的進化 (#啾啾鞋 XD)
Concatenative Speech Synthesis (拼接式合成)
拼接式合成將預錄好的語句、文字語音組成一個資料庫。當欲生成語音的文字進來時,在資料庫裡挑選適當的 example 拼接成新的語音。
然而該如何挑選語句來合成語音是一個大問題。若使用長的語句,合成出來的聲音可能比較自然,但會要求很多的 example 儲存在資料庫裡,因此會有記憶空間的問題以及該如何取得這麼多 example 的人力問題,因此彈性較低;若使用短的語句,彈性較高,但文字的標註、聲音的挑選會變得較困難、合成出來的聲音會較不自然。
Parametric Speech Synthesis (參數式合成)
參數式合成是利用訓練好的模型來合成聲音的波形,好處是他不需要像拼接式合成那樣有一個龐大的資料庫,比起拼接式合成來得更有彈性、節省人力。但是過去的實驗結果顯示,參數式方法合成出來的語音比較平淡、品質較差且不自然。
參數式合成會從語音訊號 x = {x1,…,xT} 抽取 vocoder 參數 o ={o1,…,oN} 和從文字 W 抽取語言特徵 (linguistic features) l。
訓練時使用一個生成模型 (generative model) ,可以是 HMM、類神經網路等, 希望根據語言特徵 l 產生適當的 vocoder 參數 o,最後讓 vocoder 根據這個參數 o 產生聲音波形。
Training 階段,更新模型參數 λ :
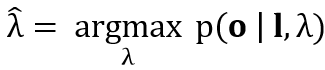
Synthesis 階段,從 linguistic features l 和模型 λ 得到 vocoder 參數 o :
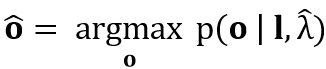
最後 vocoder 再使用這個 o 來合成聲音波形。
Deep Learning (深度學習)

近年來,隨著 deep learning 技術的發展,對 TTS 這個領域產生了重大的影響。2016年 Google DeepMind 率先提出 WaveNet 的深度學習架構 (請參考 語音合成 Part2 – WaveNet 語音生成模型),取得了很大的成功,並且投入商業應用,包含 Google助理、Google翻譯等等。日後更有 Tacotron 、Tacotron2、WaveRNN 等很厲害深度學習架構出現,這些主題將在之後的文章介紹。
如果想聽聽看上面三種方法所合成出來的聲音可以到 Google DeepMind 的部落格,裡面有對WaveNet 合成出來的語音甚至是用 WaveNet 合成出來的音樂
Reference
- Taylor, P. (2009). Text-to-speech synthesis. Cambridg`e university press.
- Khan, R. A., & Chitode, J. S. (2016). Concatenative speech synthesis: A Review. International Journal of Computer Applications, 136(3), 6.
- Hunt, A. J., & Black, A. W. (1996, May). Unit selection in a concatenative speech synthesis system using a large speech database. In 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings (Vol. 1, pp. 373-376). IEEE.
- Oord, A. V. D., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., … & Kavukcuoglu, K. (2016). Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499.
- Zen, H., Tokuda, K., & Black, A. W. (2009). Statistical parametric speech synthesis. Speech Communication, 51(11), 1039-1064.
- Black, A. W., Zen, H., & Tokuda, K. (2007, April). Statistical parametric speech synthesis. In 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07 (Vol. 4, pp. IV-1229). IEEE.