
這篇文章主要翻譯、節錄自: http://blog.ezyang.com/2019/05/pytorch-internals/
作者是 Edward Z. Yang,在Facebook工作,負責PyTorch開發。想學PyTorch跟著他的開發者學準沒錯!因為原作者的文章寫得實在是太好了,我將重點、精華節錄出來,重新理解過一次加上自己的解釋,希望能讓大家有PyTorch內部有更深的了解。
老話一句 : 現在每個人都在做機器學習,但是大部分的人都把他當作黑盒子,而不了解其底層在做什麼。懂了這些,就是你贏別人的地方,所以讓我們一起耐著性子學習這些精髓、一起變強!

這系列的文章將主要包涵兩個部份:
- 第一部份 : Concepts
- Tensor (張量) 的基本觀念 : 張量(Tensor)、儲存(Storage)、步長(Strides)
- PyTorch 三要素 : 布局(layout)、設備(device)、資料類型(dtype)
- 自動微分機制(autograd mechanics)
- 第二部份 : Mechanics
- PyTorch 內部程式碼
- PyTorch 中的 Operator Call Stack
- PyTorch Kernels
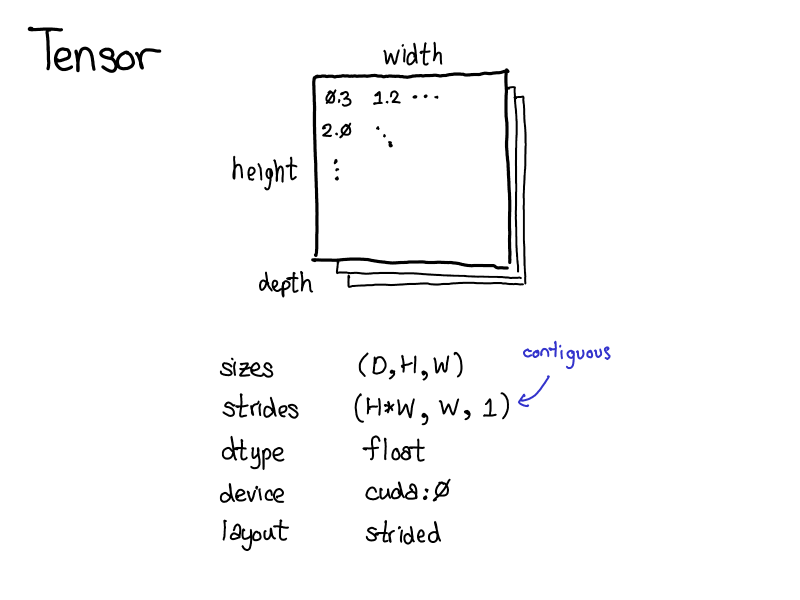
Tensor 張量
Tensor 是 PyTorch 最重要的資料結構,Tensor 是一個 n-維 (n-dimesional) 的資料型態,裡面可以容納很多純量,像是浮點數(floats)、整數(ints)等等。(可以把 Tensor 想像成更高維度的向量或矩陣,裡面包涵很多純量)
每個 Tensor 都有一些 metadata 來描述他,像是:
- sizes : Tensor的大小
- dtype : Tensor裡面元素的資料型別
- device : Tensor所在的設備,是在CPU的記憶體上?或是CUDA記憶體上?
- strides : 我們應該按照間隔步長來存取記憶體上的 Tensor 元素 (以下會詳細介紹)

Tensor : Strides Representation 步長表示法
Tensor是一個抽象的數學概念,要表達成電腦看得懂的形式,我們通常需要定義一種物理儲存的方式。最常見的方式是將Tensor中的每個元素按照順序連續的的放在記憶體上。像圖中一樣,將每一列 (row) 的元素依序放到記憶體上。
圖中的 Tensor 存放的是 32-bit 整數,所以可以看到在記憶體上的地址每格位移 4bytes。但是將 Tensor 存放在一維的記憶體上,我們還需要有額外的資訊才能還原 Tensor 的大小、維度。

Tensor 存取元素element
假設我想要存取索引(index)是[1, 0]的元素(也就是圖中的”3″),我該怎麼把邏輯位址位置(logical position)轉換成物理上的記憶體位址呢?
我們必須依靠 strides : 只需要將對應維度上的 index 和 stride 相乘,並將所有維度的乘積相加即可得到。例如下圖中,第一維用藍色表示,第二維用紅色表示,取index為[1, 0]的元素 :
- index為[1, 0]
- strides為[2, 1]
- 則$1 \times 2 + 0 \times 1 = 2$
在後面,我們會討論 TensorAccessor一個專門處理以上計算索引的類別,可以讓我們更方便找到每個元素,不用擔心指針(pointer)的操作。

Tensor 存取列row
如果想要取得 Tensor 中的一個列[1,:]也是可以的,這邊要注意的是,當我們這樣取列的時候,我們並不會再創造一個 Tensor。可以想像真實的資料都是存放在記憶體上,那個真實的資料並不會因為你多指派一個變數而改變。因此,你只是得到不同的view
view 在這邊怎麼翻譯都有點奇怪,但精神大致上是視角、觀點的意思,同樣儲存在記憶體的上資料,你可以用不同的”視角”去看他,可以把他看成一個向量、一個矩陣、指派不同變數給他等等,但是真實的資料在記憶體上就是只有一份。

也因為這樣,當你在一個 view 改動資料的時候,是會影響到你原來的那個Tensor的。這邊直接給個範例比較清楚:

Tensor : 存取行column
剛剛要取列很容易,因為在記憶體上,一個列的元素是由連續的記憶體地址來存放的。但是如果今天要取直的行(column)怎麼辦呢?這時候就需要依靠 stride:
現在我們取行的時候,stride 是 2,意思就是每個元素之間,我們在實體的記憶體要間隔 2 格來存取

Tensor小結
總結來說,Tensor要區分為使用者看到的邏輯概念和真實的儲存在記憶體上的資料。每個 Tensor 都各自紀錄了自己的大小(size)、步長(strides)等等,這些資訊定義了 Tensor 的邏輯、使用者層面(用什麼方式來看待記憶體上的資料)。
記憶體上的資料可能會對應到多個 view,就像貼標籤或是轉個視角去看這些資料一樣,資料是不變的,但是你想怎麼看他、怎麼命名都可以。
在 PyTorch 裡面 Tensor 的 logical view 和記憶體上的physical data永遠是解耦 (decoupled) 的,即使是一個非常簡單的 Tensor,像是 torch.zeros(2,2)。
