
原始論文連結
Tacotron: Towards End-to-End Speech Synthesis

Tacotron 介紹

雖然 WaveNet 在 TTS 上可以做得很好,但是他需要自行生成 linguistic features 當作 input,因此仍然不是 end-to-end 的。Tacotron 希望能做到直接使用 <text, audio> pair 來訓練model,也就是使用較少的 feature engineering 特徵工程和 heuristic 來做 TTS。 Tacotron 具有以下特色:
- End-to-End 端到端模型,使用 <text, audio> pairs 來訓練模型
- Encoder-Decoder 編碼器-解碼器的 Sequence-to-sequence 模型
- 生成語音訊號為 frame level,較 WaveNet的 sample level autoregressive 來得快
- 包含 Attention 機制 (Seq2Seq with Attention)
- Input 為 character ; Output 為 raw spectrogram
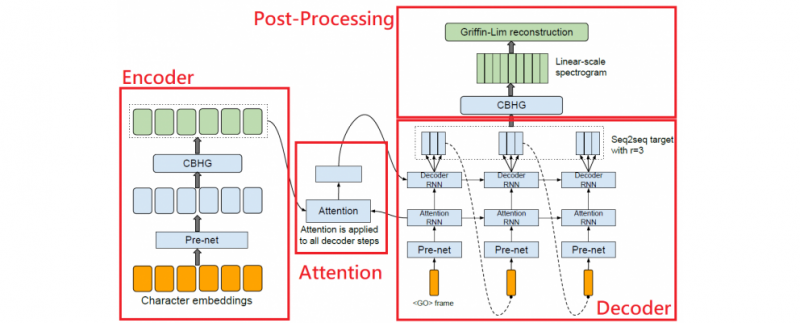
Tacotron 架構

Tacotron 可以分成四個部分:
- Encoder 編碼器
- Attention 注意力機制
- Decoder 解碼器
- Post-Processing 後處理
另外在 Encoder 和 Post-Processing 裡包含CBHG 模組
CBHG 模組
CBHG is a powerful module for extracing representations from sequences
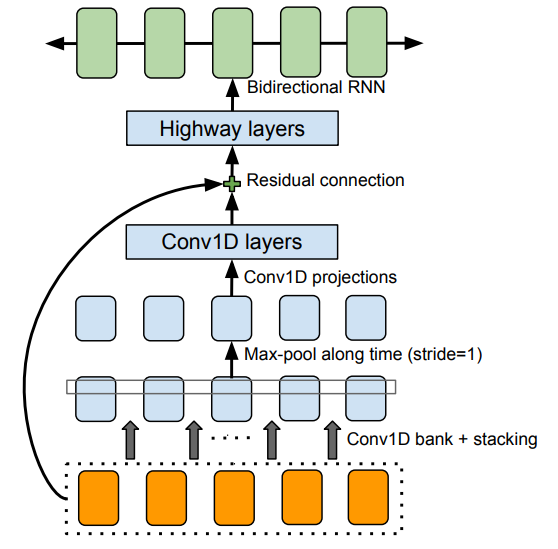
在 Tacotron 的 Enocder 和 Post-Processing Net 裡都有使用 CBHG 模組,CBHG 是受到論文 Fully Character-Level Neural Machine Translation without Explicit Segmentation (character to character 的機器翻譯,使用 1-d convolution 和 max pooling) 的啟發再加以改進而建構出來。CBHG 包含
- 1-D convolution bank (包含K個大小為1, 2, 3, … K 的 1-D filter)
- max-pooling
- highway network (請參考 Highway Networks)
- bidirectional GRU
- residual connection
之後將會寫文章為大家介紹 Residual Networks 和 Highway Networks 的原理,為什麼可以讓模型搭建得更深更多層。
Encoder 編碼器
The goal of the encoder is to extract robust sequential representations of text

- Input 為 one-hot character 的序列,並且會做 embedding 成 256 維的向量。
- 256 維的 embedding 向量會再經過一連串的非線性變換 — pre-net,pre-net 是一個 Bottleneck layer ,從 256 個神經元的全連接層 (Fully Connected) 到 128 個神經元,並且包含 Dropout。
- 再來是經過前面提到的 CBHG 模組,論文裡提到使用這個 CBHG 模組可以降低overfitting 的情形,並且會產生較少的發音錯誤 (mispronunciation)。
Attention 注意力機制
在每一個 decoder step,都使用了 Attention 。Attention 使用了一層 256 個 cells 的 GRU 。
之後會將 Decoder 中 pre-net (一樣為兩層 FC) 的輸出和經過 Attention 後的 Context Vector 作為輸入送入 Decoder RNN。
可以 Attention 的相關論文
- Neural Machine Translation by Jointly Learning to Align and Translate
- Attention Is All You Need
- Grammar as a Foreign Language
Decoder 解碼器

Decoder 由 pre-net 、Attention RNN (上述的 Attention 機制) 和 Decoder RNN (residual GRU) 所組成。
Decoder 的輸入 :
- 在 Inference 時,輸入是前一個 decoder step 的輸出
- 在 Training 時,輸入是 Ground Truth,使用正確答案來訓練 (Teacher Forcing)
Decoder 的輸出 :
- 80-band 的 mel-scale spectrogram
論文裡提到一個重要的 trick : 每一個 decoder step 都預測 “多個”、”不重疊”的 frame,目的是減少需要 predict 的次數。一次預測 r 個 frame 的 decoder step 是一次只預測 1 個frame 的 1 / r。可以達到 :
- 加快訓練速度
- 提升Inference的速度
- 減少 Model 的大小
- 加快收斂速度
Post-Processing 後處理
Post-Processing 的目的是將 Decoder 的 Output 轉換成可以合成 waveform 的形式。而論文裡使用 Griffin-Lim 來合成 Waveform,因此論文中 Post-Processing Net 由一個 CBHG module 組成並將 mel-scale spectrogram 轉換成 linear-scale spectrogram。
另外一個使用 Post-Processing Net 的優點是,不像 seq2seq 只能從左到右運行,他可以有正向和反向的資訊流動,同時看左又看右,因此可以校正 decoder 的 output。
最值得注意的一點是這個 Post-Processing 其實是可以替換成預測其他東西的,像是之後有非常多的研究不是用 Griffin-Lim,也不是使用 linear-scale spectrogram,而是使用 mel-spectrogram 以及語音合成 Part2 提到的 WaveNet。
Tacotron 實驗與結論
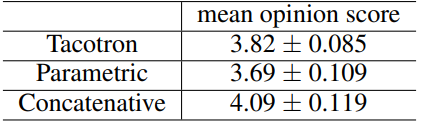
在實驗中, Dataset 與 WaveNet 論文中做的實驗一樣使用的是North American English Dataset。成效可以比 Parametric 的方法好。
Tacotron 的重點在於他提出了一個很好的 End-to-end 的 TTS 架構。另外 seq2seq target 以及 post processing 後的 output 是可以換成其他型態的。雖然這篇論文的實驗結果不是很出色,但 Tacotron 開了一個很好的頭,之後還有很多研究是基於 Tacotron 以及 WaveNet 而且達成了很厲害的成果。將在語音合成專題的後面繼續為大家介紹!
Reference
- Wang, Yuxuan, et al. “Tacotron: Towards end-to-end speech synthesis.” arXiv preprint arXiv:1703.10135 (2017).
- He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Srivastava, Rupesh Kumar, Klaus Greff, and Jürgen Schmidhuber. “Highway networks.” arXiv preprint arXiv:1505.00387 (2015).
- Lee, Jason, Kyunghyun Cho, and Thomas Hofmann. “Fully character-level neural machine translation without explicit segmentation.” Transactions of the Association for Computational Linguistics 5 (2017): 365-378.
- Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).
- Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
- Vinyals, Oriol, et al. “Grammar as a foreign language.” Advances in neural information processing systems. 2015.