
前言 – 阿嬤碎碎念
聲明:本網站上的爬蟲教學為純粹技術分享,請不要進行大量、高頻的爬蟲做出不正當的行為,造成他人的困擾及損害他人的權利!
今天我們將從 臺灣證券交易所 爬取台積電的股價及其他日成交資訊,包含:
日期、成交股數、成交金額、開盤價、最高價、收盤價、漲跌價差、成交筆數
我們可以從證交所的 個股日成交資訊 網頁查詢到上市股票的股價等資訊。這篇文章將以台積電 (代號 2330為例),若你對其他標的有興趣,也可將 2330 代換成其他公司代碼。
資料來源 : 臺灣證券交易所
聲明:本網站上的爬蟲教學為純粹技術分享,請不要進行大量、高頻的爬蟲做出不正當的行為,造成他人的困擾及損害他人的權利!

我們使用 Python 爬取股價時將使用 列印 / HTML 那個網頁,請點進去。網址是

再看看 2020 年1月份的

再看一次網址
二月份:
https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date=20200224&stockNo=2330
一月份:
https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date=20200101&stockNo=2330仔細觀察網址,有沒有發現只有在 date 的欄位有差別,他其實是有一個版型的。date 後面接日期,stockNo 後面接股票代碼,因此這段網址就是 2020年2月 代號為 2330 的日成交資訊 (經過測試年月日的日是不重要的,填20200201也可以得到一樣的資訊)。
爬蟲不難,只要發現資料來源的規律就可以撰寫程式將內容自動爬下來。
Pandas、requests 爬取網頁
我們將使用 Python 的 requests 以及Pandas 套件將我們看到的那些資料爬取下來,先安裝套件,雖然在 python 程式碼裡面不會用到,但是需要手動安裝 lxml 來給 pandas 用,不然會出現錯誤
$ pip install pandas
$ pip install requests
$ pip install lxml安裝完後就可以將他們 import 進來
import requests
import pandas as pd接下來就可以試著爬取二月份 資訊
url = "https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date=20200224&stockNo=2330"pd.read_html()
requests.get()
爬下來會是一個 dataframe 的陣列,取第一個[0]
data = pd.read_html(requests.get(url).text)[0]使用 Spyder3 可以直接在 workspace 點擊兩下變數看看長怎樣 ( Spyder 非常讓人喜歡的一個地方)

可以發現各項資料都被我們抓下來了,只是欄位 (column name) 的名字有點奇怪
data.columnsMultiIndex([(‘109年02月 2330 台積電 各日成交資訊’, ‘日期’),
(‘109年02月 2330 台積電 各日成交資訊’, ‘成交股數’),
(‘109年02月 2330 台積電 各日成交資訊’, ‘成交金額’),
(‘109年02月 2330 台積電 各日成交資訊’, ‘開盤價’),
(‘109年02月 2330 台積電 各日成交資訊’, ‘最高價’),
(‘109年02月 2330 台積電 各日成交資訊’, ‘最低價’),
(‘109年02月 2330 台積電 各日成交資訊’, ‘收盤價’),
(‘109年02月 2330 台積電 各日成交資訊’, ‘漲跌價差’),
(‘109年02月 2330 台積電 各日成交資訊’, ‘成交筆數’)],
)
更改一下這個 dataframe 的 column name
data.columns = data.columns.droplevel(0)就可以得到非常漂亮的 data 了!

我們可以將他存成 CSV 檔日後需要利用時再讀取就可以了。
data.to_csv('2330_20200201.csv', index=False)爬取多個月份
學會爬取二月份的台積電日成交資訊後,我們只要修改部份程式碼就可以爬取多個月份的資料。
將我們想要的日期放到一個 list 裡面
dates = [20200201, 20200101, 20191201]將上面我們觀察到的網址寫成一個字串版型,之後將使用字串取代 format 函式,因此在將會取代掉的地方放上大括號 {}
url_template = "https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date={}&stockNo={}"再寫成一個 for 迴圈將每個月的資料都爬取一次就大功告成!
完整程式碼
聲明:本網站上的爬蟲教學為純粹技術分享,請不要進行大量、高頻的爬蟲做出不正當的行為,造成他人的困擾及損害他人的權利!
import requests
import pandas as pd
dates = [20200201, 20200101, 20191201]
stockNo = 2330
url_template = "https://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date={}&stockNo={}"
for date in dates :
url = url_template.format(date, stockNo)
file_name = "{}_{}.csv".format(stockNo, date)
data = pd.read_html(requests.get(url).text)[0]
data.columns = data.columns.droplevel(0)
data.to_csv(file_name, index=False)實際使用Office軟體打開存好的 CSV 檔看看
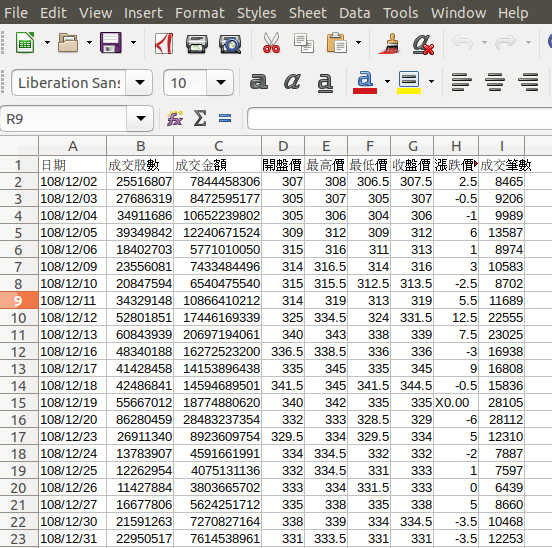
結論
- 這次教大家使用 Python中的 Pandas 以及 Requests 來爬取台積電的歷史日成交資訊。讀者也可以替換成其他公司來試試。
- 有些網站會把爬蟲程式擋下來,以及如果短時間內存取該網頁太多次,IP 會被鎖。日後將寫文章跟大家說如何應對這種情形。請參考 Python 爬蟲教學:爬蟲進化 – 偽裝篇 fake_useragent 介紹
- 本篇文章是使用 CSV 檔將檔案存起來,但是日後若資料量非常大,則使用資料庫(如 MySQL)來存放資料是較好的選擇。請參考 Python – 股票爬蟲 – 市場分析 : 串接 MySQL資料庫
data = pd.read_html(requests.get(url).text)[0] 為何要取第一個[0]呀?
這是因為 pd.read_html 這個函式會回傳 DataFrame 的 list:
Return: dfs –> A list of DataFrames.
(參考: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_html.html)
一個網站上面可能會包含多個表格,pd.read_html 會抓到每一個表格,並且把他們都裝在 list 裡面。
使用Office軟體開啟CSV後發現欄位格式錯誤,其他皆正常,請問是甚麼問題採導致這種情況發生?
應該是在開啟CSV檔案時,沒有選擇到對的”分隔符號”,導致Office軟體沒有辦法辨別總共有幾個欄位等等。
可以在匯入時 (以Excel為例) 使用 “取得外部資料的「從文字檔」” 並且在 “匯入字串精靈” 選擇分隔符號。
跟著版主的步驟照做,問題已解決。謝謝
請問為何抓下來只看到一個月的資料?