

前言
在先前我們已經針對威力彩的分析出了兩篇文章,告訴大家威力彩爬取資料的方法與基本的分析,很感謝有讀者對於威力彩的分析有後續想法,因此私訊告訴我們,所以本篇文章的分析會著重於,如果這一期出現幾號球則下一期出現哪些號球的可能性會比較大,感謝讀者提供這個想法,我們也用簡單的方法,告訴大家如何達成此目的,也希望讀者有各種想法,可以私訊告訴我們,假如我們有能力會盡力做出來跟大家分享,之後平台也會出高質量非常便宜的付費文章,再請大家多多支持。
第一階段資料爬取處理
import requests
import pandas as pd
from io import StringIO
import datetime as dturl='https://www.pilio.idv.tw/lto/listbbk.asp?indexpage=1&orderby=new'
r=requests.get(url)
r.encoding='big5'
dfs=pd.read_html(StringIO(r.text))
df=dfs[1]
df.head()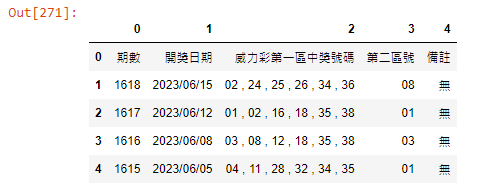
url='https://www.pilio.idv.tw/lto/listbbk.asp?indexpage={}&orderby=new'
for i in range(2,55):
r=requests.get(url.format(i))
r.encoding='big5'
dfs=pd.read_html(StringIO(r.text))
dfs=dfs[1]
df=pd.concat([df,dfs])
df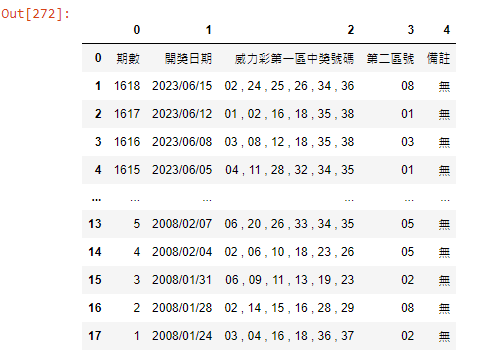
df=df[df[0]!='期數']
df.columns=['期數','日期','第一區','第二區','備註']
df=df[::-1]
df=df.set_index('期數',drop=True)
df['日期']=pd.to_datetime(df['日期'])
df['星期']=df['日期'].dt.dayofweek
df['星期']=df['星期']+1
df['第一區下一期']=df['第一區'].shift(-1)
df.head()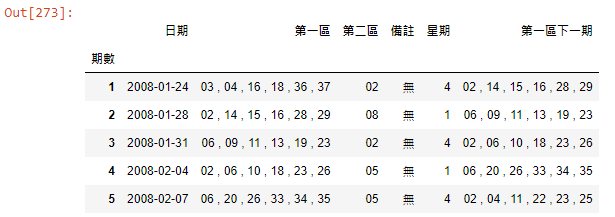
df_1=df['第一區'].str.split(',',expand=True)
df_1.columns=['第一','第二','第三','第四','第五','第六']
df_1['第二區']=df['第二區']
df_1['星期']=df['星期']
df_1=df_1.astype(int)
df_1['日期']=df['日期']
df_1.head()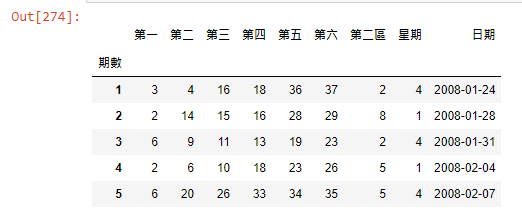
df_1['第一區']=df_1['第一'].astype(str) + ',' + df_1['第二'].astype(str)+',' + df_1['第三'].astype(str)
df_1['第一區']=df_1['第一區']+ ',' + df_1['第四'].astype(str)+',' + df_1['第五'].astype(str)+ ',' + df_1['第六'].astype(str)
df_1.head()
以上為資料分析前的資料處理做法,詳細的介紹在 Python 威力彩分析(上):爬蟲、Pandas表格處理大家有興趣可以先去看這篇文章的介紹,對於分析有興趣的人可以參考這篇 Python 威力彩分析(下):爬蟲、Pandas表格處理
第二階段進行資料分析
將下一期資料往前移
df_1['第一區下一期']=df_1['第一區'].shift(-1)
df_1['第二區下一期']=df_1['第二區'].shift(-1)
df_1.tail()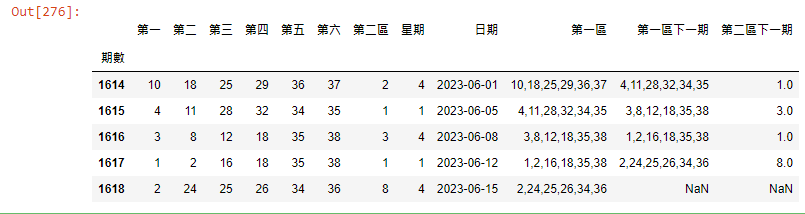
接下來就是要開始完成我們這篇文章的想法了,這個步驟是最重要的一步,我們把下一期的資料,往前推移到這一期,並新增兩個欄位 “第一區下一期” 與 “第二區下一期” ,如此一來我們就能進行分析了,shift() 這個函數相當好用,大家可以善加利用。
刪除遺漏值
df_1=df_1.iloc[:-1,:]
df_1['第二區下一期']=df_1['第二區下一期'].astype(int)
df_1.tail()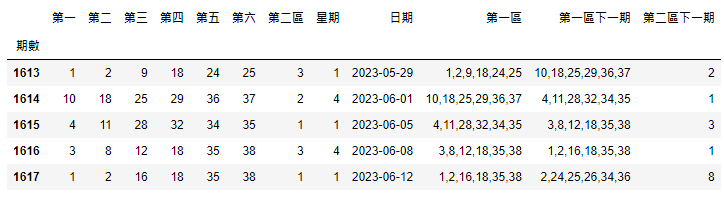
由於最後一期的資料還沒有下一期的資料,所以根據上一張圖會看到,最後一欄出現”NaN”,因此我們刪除最後一欄的資料,才不會對後續的分析造成程式碼錯誤的影響,再將”第二區下一期”此欄轉成整數型態。
第一區號球分析
當這一期出現38號球下一期會出現幾號球
num=[38]
df_1['sigh']=df_1[df_1.iloc[:,:6].isin(num)==True].count(axis=1)
target=df_1[df_1['sigh']==1]
from itertools import combinations
from collections import Counter
count=Counter()
for row in target['第一區下一期']:
row_list=row.split(',')
count.update(Counter(combinations(row_list,1)))
for key,value in count.most_common(10):
print(key,value,value/len(target))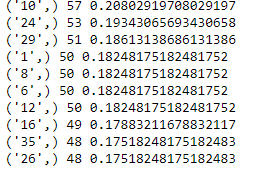
首先我們在num裡面放入 “38號”,接著建立一個新欄位為 “sigh”,威力彩的第一區會依序開出六顆球,因此只要第一到第六出現過 “38號”,則此時”sigh”的總合會是1,因為只要出現一個True,經過count(axis=1)計算過後,就會出現1,因此此時根據這些”sigh”有符合的資料,建立一個新表格即可,我們此時再針對新表格的”第一區下一期”欄位,進行統計分析就可以了,由結果可以知道,這一期出現 “38號” 球的下一期,有可能出現的前十大號球,其中 “10號”球為最常出現的號球,出現次數57次,在這一期出現38號的情況下,下一期出現的機率為0.2080。
當這一期出現38號與35號下一期會出現幾號球
num=[38,35]
df_1['sigh']=df_1[df_1.iloc[:,:6].isin(num)==True].count(axis=1)
target=df_1[df_1['sigh']==2]
from itertools import combinations
from collections import Counter
count=Counter()
for row in target['第一區下一期']:
row_list=row.split(',')
count.update(Counter(combinations(row_list,1)))
for key,value in count.most_common(10):
print(key,value,value/len(target))
首先我們在num裡面放入38號與35號,接著建立一個新欄位為”sigh”,威力彩的第一區會依序開出六顆球,因此只要第一到第六同一期出現過 “38”號與”35″號,則此時”sigh”的總合會是2,因為只要出現兩個True,經過count(axis=1)計算過後,就會出現2,因此此時根據這些”sigh”有符合的資料,建立一個新表格即可,我們此時再針對新表格的”第一區下一期”欄位,進行統計分析就可以了,由結果可以知道,這一期出現 “38號”與”35號” 球的下一期,有可能出現的前十大號球,其中 “28號”球 為最常出現的號球,出現次數11次,在這一期同時出現 “38號”與”35號” 的情況下,下一期出現 “28號” 球的機率為0.2619。
num=[38,35,18]
df_1['sigh']=df_1[df_1.iloc[:,:6].isin(num)==True].count(axis=1)
target=df_1[df_1['sigh']==3]
from itertools import combinations
from collections import Counter
count=Counter()
for row in target['第一區下一期']:
row_list=row.split(',')
count.update(Counter(combinations(row_list,1)))
for key,value in count.most_common(10):
print(key,value,value/len(target))
這裡在條件當中加入 “18號”,並選取sigh=3的資料即可,其餘都跟上述方法一樣,我們可以觀察到當我們加入的號球條件越多時,雖然符合的資料越少,但此時下一期出現特定的球號機率也會比較高,
第二區號球分析
當這一期第二區出現三號下一期第二區會出現幾號球
i=3
df_1[df_1['第二區']==i]['第二區下一期'].value_counts()/len(df_1[df_1['第二區']==i])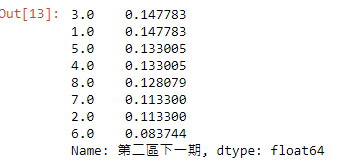
威力彩的第二區就是1到8號,因此大家可以改i去分析,一般而言8顆球在隨機的情況下,每一顆球出現的機率是0.125,因此本分析i=3的情況下,即這一期的第二區出現 3號球,則下一期第二區出現的號球次數最多為 “3號”與”1號”,機率皆為0.1477,而且有5種號球出現的機率高於平均的0.125, “6號” 則是在此情況下最不常出現的號球,機率僅有0.083。
結論與建議
感謝讀者私訊,讓我們得到這個想法,並做出來跟大家分享,希望大家都能學習到一些程式碼上的運用與學習,然而還是要跟大家說,分析可能可以讓你有條件地買樂透,但畢竟這種東西運氣還是最重要的,所以大家可以參考參考,千萬不要過度著迷,希望大家往後對我們的文章有任何想法都可以私訊我們的臉書粉專,也請大家期待接下來的付費文章,有興趣的讀者也可以支持我們一下,感謝大家的觀閱。

作者:TKH
企業管理學碩士,對 Python、資料科學有滿滿的熱忱,就讀碩士期間開始學習程式語言、機器學習,並於碩士論文使用深度學習 LSTM 進行股價預測。